Test AI On Your Terms, Not Theirs
The New York Times reports that AI is getting more powerful, but its hallucinations are getting worse. It turns out that non-reasoning models are improving, while reasoning models like OpenAI’s o3 and o4-mini — based on its own testing — showed increased hallucination rates of 33% (PersonQA) and 79% (SimpleQA) respectively.
Nathan Lambert points out that the reason models are crushing obscure tests such as MMLU, GPQA, MATH, SWE-Bench, and others is because they are being trained to ace those tests. Kind of like SAT test prep: get good at taking tests that lack real-world relevancy.
Simon Willison summarizes recent controversy regarding Meta (and others) gaming the influential Chatbot Arena by testing multiple variants of its Llama 4 model. “…it turned out that their model which topped the leaderboard wasn’t the same model that they released to the public!” The paper revealed Meta tested 27 private LLM variants before the Llama-4 release.
So what can you believe? You can trust the performance evaluations that align with your use cases. How well does your system of agents, frameworks, LLMs, and data give you acceptable answers? When you optimize prompts, models, and tools, are you continuously testing against your ground truth?
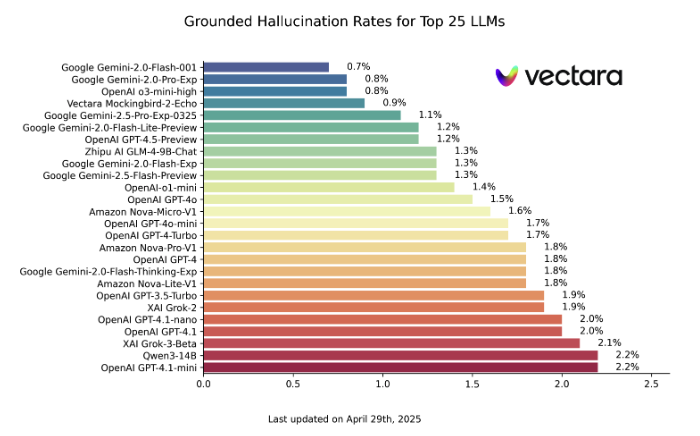
Vectara Hallucination Leaderboard
Vectara provides an interesting example. Since 2023, Vectara has measured hallucination rates on an evaluation system based on a very common use case — retrieval augmented generation (RAG). They feed 1,000 short documents into each LLM to measure the rate of factually-based answers.
BTW, Vectara has seen a steady decline in hallucination rates with Google Gemini-2.0-Flash-001 having the lowest levels of mistakes at 0.7%, whereas reasoning models OpenAI o3 (6.8%) and DeepSeek R1 (14.3%) are higher. Confusingly, OpenAI o3-mini-high has a low hallucination rate (0.8%).
The only solution for building performant LLM applications and testing optimization is to invest in your own use case-based evaluation system.