Evaluation-driven multi model/tool path to 5-10x gains
An AI tool was producing subpar results. We flipped the script, achieving a 5x accuracy lift and a 10x productivity gain.
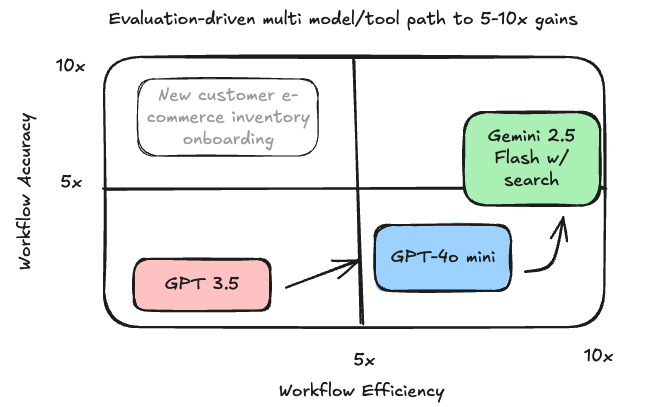
A company I advise was dissatisfied with an AI-powered workflow. The goal was to onboard new customer inventory, generate personalized product descriptions, and include precise specifications.
Evaluation-driven multi model/tool improvement. Image: gemini and chatgpt
Their existing GPT-3.5 tool, state-of-the-art at the time, fell short. The descriptions were generic, and the specs were often wrong. This created a painful rework loop for the team, defeating the purpose of the tool entirely.
Instead of just upgrading to the best-rated frontier model, I advised them to run a structured test. We evaluated a matrix of options: frontier vs. downsized models, with and without search tools for fact-finding, and using single-shot examples of a customer’s writing for personalization.
We found success not in a single tool, but in a multi-model workflow where each component excelled at its specific task.
GPT-4o mini delivered fast, inexpensive, and stylistically aligned descriptions. A small snippet of a customer’s existing web copy was all it took to align the tone. For the high-accuracy specs, Gemini 2.5 Flash with search integration proved superior.
The results were immediate and dramatic, leading to a 5x accuracy lift and 10x productivity gain.
The principle here is critical for every AI leader. The most significant performance gains don’t come from chasing the latest model on a leaderboard. They come from a rigorous, empirical process of matching the right model—and the right integrated tools—to a specific business task.